Using R Programming & Text Analysis On The Dr. Seuss - The Cat In The Hat Kids Book
Hi there. In this page, I share some experimental work in the programming language R. I use R and text analysis to analyze the words in the Dr. Seuss - The Cat In The Hat kids book.

Image Source: http://wooderice.com/wp-content/uploads/2014/04/catinthehat.jpg
{kind=link}
Sections
- Introduction
- Wordclouds On The Most Common Words In The Cat In The Hat
- Most Common Words Plot
- Sentiment Analysis On The Cat In The Hat
- References
Introduction
A text version of the book can be found from https://github.com/robertsdionne/rwet/blob/master/hw2/drseuss.txt. The contents are copied and pasted to a different .txt file for offline use.
The R packages that are loaded in are:
- dplyr
- tidyr
- ggplot2
- tidytext
- wordcloud
- tm
# Text Mining on the Dr. Seuss - The Cat In The Hat Kids Book
# Text Version Of Book Source:
# https://github.com/robertsdionne/rwet/blob/master/hw2/drseuss.txt
# 1) Wordclouds
# 2) Word Counts
# 3) Sentiment Analysis - nrc, bing and AFINN Lexicons
#----------------------------------
# Load libraries into R:
# Install packages with install.packages("pkg_name")
library(dplyr)
library(tidyr)
library(ggplot2)
library(tidytext)
library(wordcloud)
library(tm)
Wordclouds Of The Most Common Words In The Cat In The Hat Book
To start, I load in the The Cat In The Hat book from the offline text file with the readLines() function. Afterwards, the readLines() object is put into a VectorSource and then into a Corpus.
Once you have the Corpus object, the tm_map() functions can be used to clean up the text. Options include removing punctuations, converting text to lowercase, removing numbers, removing whitespace and removing stopwords (words like the, and, or, for, me).
# 1) Wordclouds
# Reference: http://www.sthda.com/english/wiki/text-mining-and-word-cloud-fundamentals-in-r-5-simple-steps-you-should-know
# Ref 2: https://www.youtube.com/watch?v=JoArGkOpeU0
catHat_book <- readLines("cat_in_the_hat_textbook.txt")## Warning in readLines("cat_in_the_hat_textbook.txt"): incomplete final line
## found on 'cat_in_the_hat_textbook.txt'catHat_text <- Corpus(VectorSource(catHat_book))
# Clean the text up:
catHat_clean <- tm_map(catHat_text, removePunctuation)## Warning in tm_map.SimpleCorpus(catHat_text, removePunctuation):
## transformation drops documentscatHat_clean <- tm_map(catHat_clean, content_transformer(tolower))## Warning in tm_map.SimpleCorpus(catHat_clean, content_transformer(tolower)):
## transformation drops documentscatHat_clean <- tm_map(catHat_clean, removeNumbers)## Warning in tm_map.SimpleCorpus(catHat_clean, removeNumbers): transformation
## drops documentscatHat_clean <- tm_map(catHat_clean, stripWhitespace)## Warning in tm_map.SimpleCorpus(catHat_clean, stripWhitespace):
## transformation drops documents# Remove English stopwords such as: the, and or, over, under, and so on:
catHat_clean <- tm_map(catHat_clean, removeWords, stopwords('english'))## Warning in tm_map.SimpleCorpus(catHat_clean, removeWords,
## stopwords("english")): transformation drops documents
The next step is to convert the tm_map() object in a Term Document Matrix and then into a data frame. Once a data frame is obtained, wordclouds along with bar graphs can be generated.
# Convert to Term Document Matrix:
td_mat<- TermDocumentMatrix(catHat_clean)
matrix <- as.matrix(td_mat)
sorted <- sort(rowSums(matrix),decreasing=TRUE)
data_text <- data.frame(word = names(sorted), freq = sorted)
#Preview data:
head(data_text, 30)## word freq
## like like 88
## will will 58
## said said 43
## sir sir 37
## one one 35
## fish fish 34
## house house 29
## cat cat 29
## say say 29
## now now 29
## things things 26
## fox fox 26
## eat eat 26
## grinch grinch 26
## two two 25
## can can 25
## box box 25
## look look 24
## thing thing 22
## socks socks 22
## hat hat 20
## know know 20
## hop hop 18
## good good 17
## new new 17
## knox knox 17
## little little 16
## mouse mouse 16
## bump bump 15
## saw saw 15
The wordcloud() function from the wordcloud package allows for the generation of a colourful wordcloud as shown below.
# Wordcloud with colours:
set.seed(1234)
wordcloud(words = data_text$word, freq = data_text$freq, min.freq = 5,
max.words = 100, random.order=FALSE, rot.per=0.35,
colors = rainbow(30))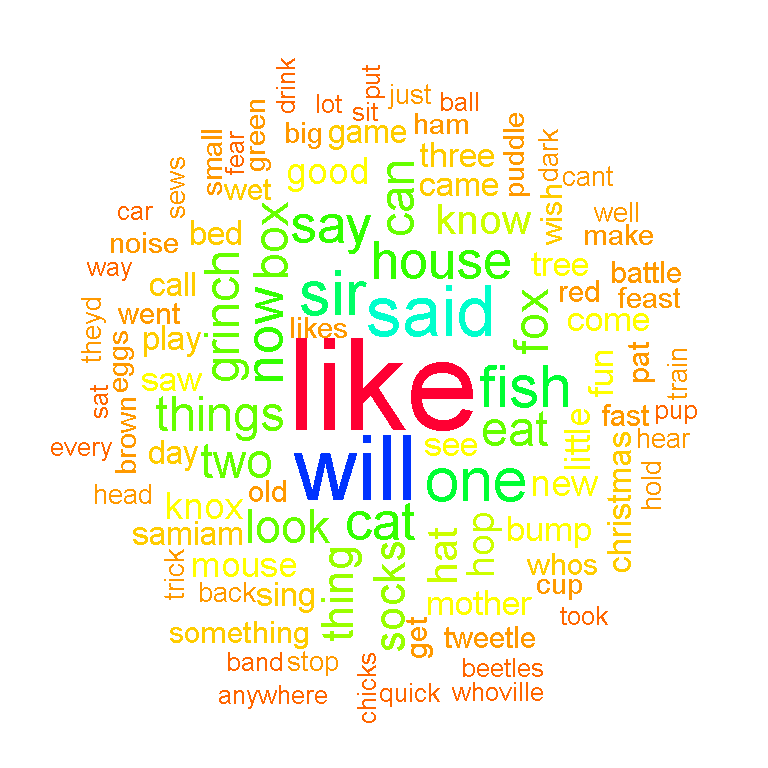
To make the wordcloud smaller you can raise the minimum frequency requirement for words by changing the value of the min.freq argument in wordcloud().
# Wordcloud with colours with lower max words and raise minimum frequency:
wordcloud(words = data_text$word, freq = data_text$freq, min.freq = 15,
max.words = 80, random.order=FALSE, rot.per=0.35,
colors = rainbow(30))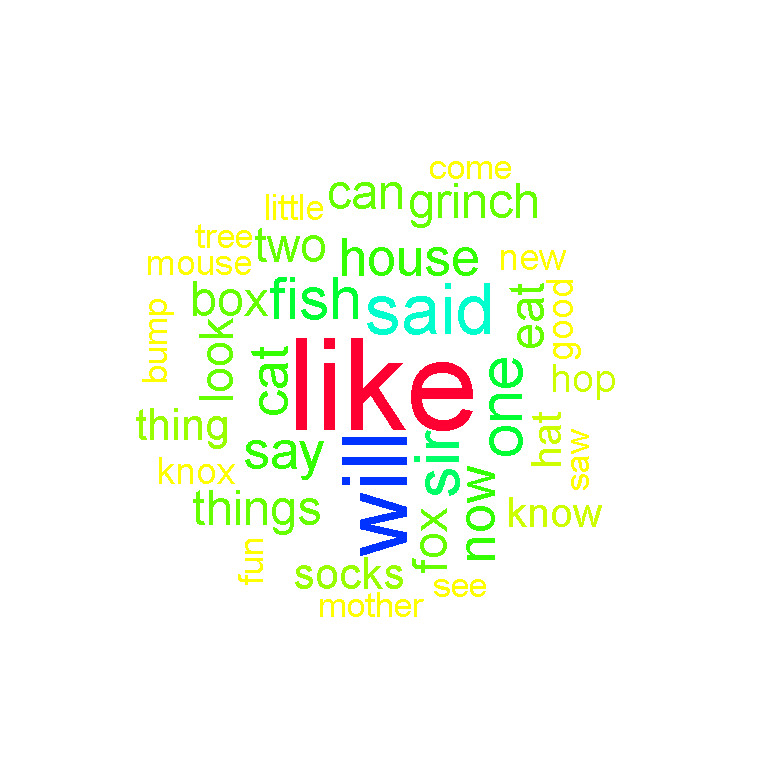
It appears that the word like is the most common along with the words will, sir, fish, things and grinch.
The Most Common Words In The Cat In The Hat Book
In my other text mining/analysis projects in R pages, I use the tidytext approach with the tidytext package and the unnest_tokens() function to obtain the most common words in the The Cat In The Hat book. However, in this page I still use code from the previous section. The data_text object is already preprocessed with the tm_map() functions and is ready for plotting with ggplot2.
I take the top 25 most common words from The Cat In The Hat book. To obtain the bars, you need the geom_col() function. Sideways bars can be obtained with the coord_flip() addon function. Labels and text can be added with the labs() function and the geom_text function respectively. The theme() function allows for adjustment of aesthetics such as text colours, text sizes and so forth.
# Wordcounts Plot:
# ggplot2 bar plot (Top 25 Words)
data_text[1:25, ] %>%
mutate(word = reorder(word, freq)) %>%
ggplot(aes(word, freq)) +
geom_col(fill = "lightblue") +
coord_flip() +
labs(x = "Word \n", y = "\n Count ", title = "Word Counts In \n The Cat In The Hat Book \n (Top 25) \n") +
geom_text(aes(label = freq), hjust = 1.2, colour = "black", fontface = "bold", size = 3.7) +
theme(plot.title = element_text(hjust = 0.5, colour = "darkgreen", size = 15),
axis.title.x = element_text(face="bold", colour="darkblue", size = 12),
axis.title.y = element_text(face="bold", colour="darkblue", size = 12),
panel.grid.major = element_blank(),
panel.grid.minor= element_blank())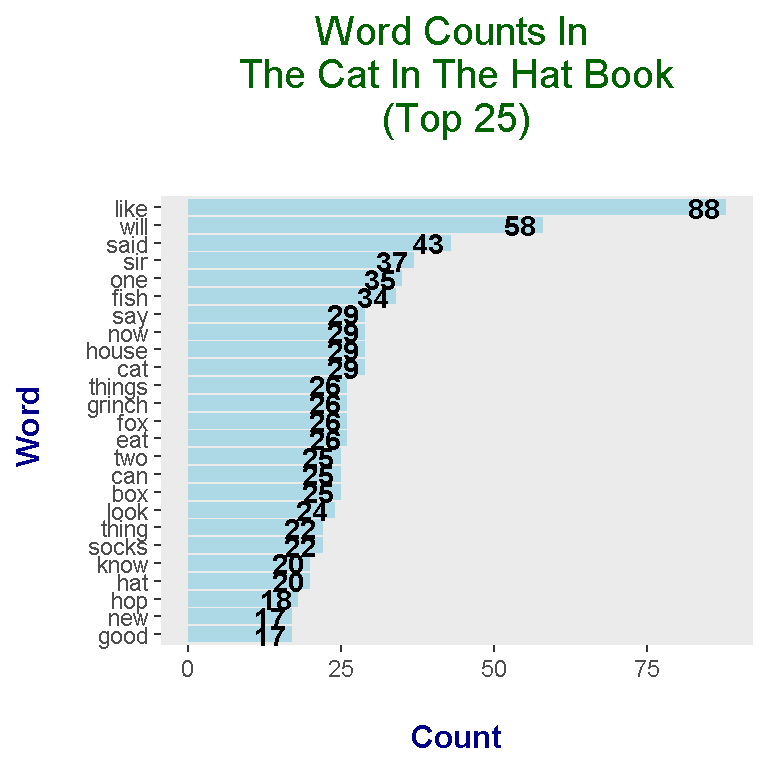
In the wordclouds, you were unable to determine the counts associated with each word. With the bar graph with numeric texts, you can clearly see the counts with the words.
The most common words in The Cat In The Hat include like, will, said, sir, one, fish and say.
Sentiment Analysis
Sentiment analysis looks at a piece of text and determines whether the text is positive or negative (depending on the lexicon). Three lexicons are used here for analyzing words.
Do keep in mind that each lexicon has its own way of scoring the words in terms of positive/negative sentiment. In addition, some words are in certain lexicons and some words are not. These lexicons are not perfect as they are subjective with the scoring.
I read in the book into R (again) and convert the book into a tibble (neater data frame). The head() function is used to preview/check the start of the book.
# 3) Sentiment Analysis
# Is the book positive, negative, neutral?
catHat_book <- readLines("cat_in_the_hat_textbook.txt")## Warning in readLines("cat_in_the_hat_textbook.txt"): incomplete final line
## found on 'cat_in_the_hat_textbook.txt'# Preview the start of the book:
catHat_book_df <- data_frame(Text = catHat_book) # tibble aka neater data frame
head(catHat_book_df, n = 15)## # A tibble: 15 x 1
## Text
## <chr>
## 1 The sun did not shine.
## 2 It was too wet to play.
## 3 So we sat in the house
## 4 All that cold, cold, wet day.
## 5 ""
## 6 I sat there with Sally.
## 7 We sat there, we two.
## 8 "And I said, \"How I wish"
## 9 "We had something to do!\""
## 10 ""
## 11 Too wet to go out
## 12 And too cold to play ball.
## 13 So we sat in the house.
## 14 We did nothing at all.
## 15 ""
The unnest_tokens() function is then applied on the data_frame() object. Each word in The Cat In The Hat now has its own row. An anti_join() is used to remove English stop words such as the, and, for, my, myself. A count() function is used to obtain the counts for each word with the sort = TRUE argument.
catHat_book_words <- catHat_book_df %>%
unnest_tokens(output = word, input = Text)
# Retrieve word counts as set up for sentiment lexicons:
catHat_book_wordcounts <- catHat_book_words %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)## Joining, by = "word"
nrc Lexicon
The nrc Lexicon categorizes words as either having the sentiment of trust, fear, negative, sadness, fear, anger or positive. Here, the sentiments of interest from the nrc lexicon are negative and positive.
#### Using nrc, bing and AFINN lexicons
word_labels_nrc <- c(
`negative` = "Negative Words",
`positive` = "Positive Words"
)
### nrc lexicons:
# get_sentiments("nrc")
catHat_book_words_nrc <- catHat_book_wordcounts %>%
inner_join(get_sentiments("nrc"), by = "word") %>%
filter(sentiment %in% c("positive", "negative"))
# Preview common words with sentiment label:
head(catHat_book_words_nrc, n = 12)## # A tibble: 12 x 3
## word n sentiment
## <chr> <int> <chr>
## 1 sir 37 positive
## 2 eat 26 positive
## 3 fun 16 positive
## 4 mother 15 negative
## 5 mother 15 positive
## 6 tree 15 positive
## 7 sing 13 positive
## 8 battle 11 negative
## 9 green 10 positive
## 10 noise 10 negative
## 11 goo 9 negative
## 12 trick 9 negative
Here is the code and output for the word counts influenced by the nrc Lexicon for The Cat In The Hat book. There is a lot of code in the section below as I wanted to make the plot look nicer than usual.
# Sentiment Plot with nrc Lexicon (Word Count over 5)
catHat_book_words_nrc %>%
filter(n > 5) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = sentiment)) +
geom_bar(stat = "identity", position = "identity") +
geom_text(aes(label = n), colour = "black", hjust = 1, fontface = "bold", size = 3) +
facet_wrap(~sentiment, nrow = 2, scales = "free_y", labeller = as_labeller(word_labels_nrc)) +
labs(x = "\n Word \n", y = "\n Word Count ", title = "Negative & Positive Words In \n The Cat In The Hat Kids' Book \n With The nrc Lexicon \n") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_text(face="bold", colour="darkblue", size = 12),
axis.title.y = element_text(face="bold", colour="darkblue", size = 12),
strip.background = element_rect(fill = "lightblue"),
strip.text.x = element_text(size = 10, face = "bold")) +
scale_fill_manual(values=c("#FF0000", "#01DF3A"), guide=FALSE) +
coord_flip()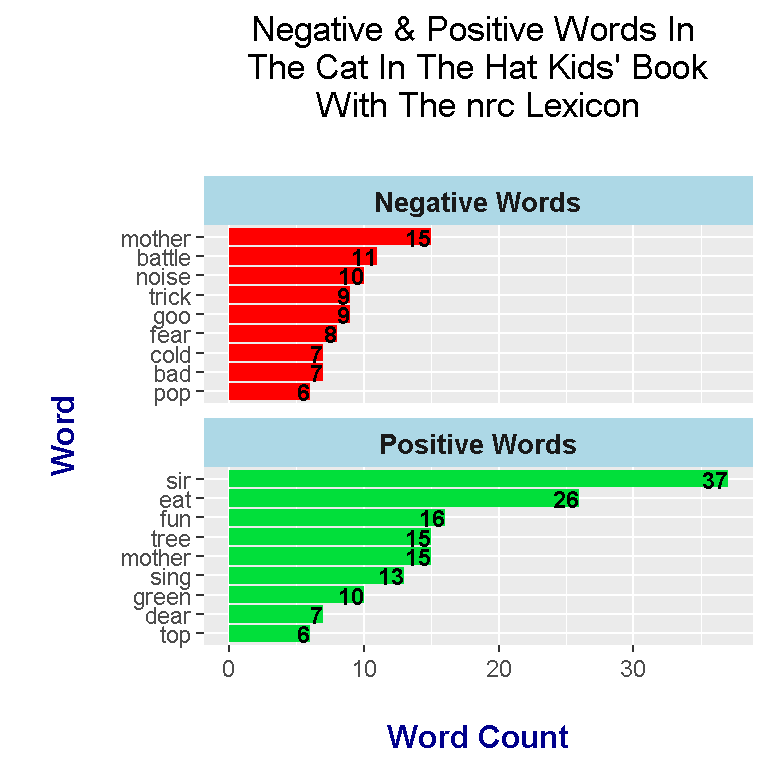
bing Lexicon
Words under the bing lexicon categorizes certain words as either positive or negative. In the bar plot below, you will see that the selected top words are different than the ones from the nrc lexicon. (These lexicons are subjective.)
### bing lexicon:
# get_sentiments("bing")
word_labels_bing <- c(
`negative` = "Negative Words",
`positive` = "Positive Words"
)
catHat_book_words_bing <- catHat_book_wordcounts %>%
inner_join(get_sentiments("bing"), by = "word") %>%
ungroup()
# Preview the words and counts:
head(catHat_book_words_bing, n = 15)## # A tibble: 15 x 3
## word n sentiment
## <chr> <int> <chr>
## 1 fun 16 positive
## 2 bump 15 negative
## 3 fast 11 positive
## 4 likes 10 positive
## 5 noise 10 negative
## 6 dark 9 negative
## 7 trick 9 negative
## 8 fear 8 negative
## 9 bad 7 negative
## 10 cold 7 negative
## 11 sad 7 negative
## 12 slow 7 negative
## 13 top 6 positive
## 14 fall 5 negative
## 15 funny 5 negative
# Sentiment Plot with bing Lexicon (Counts over 3):
catHat_book_words_bing %>%
filter(n > 3) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = sentiment)) +
geom_bar(stat = "identity", position = "identity") +
geom_text(aes(label = n), colour = "black", hjust = 1, fontface = "bold", size = 3) +
facet_wrap(~sentiment, nrow = 2, scales = "free_y", labeller = as_labeller(word_labels_bing)) +
labs(x = "\n Word \n", y = "\n Word Count ", title = "Negative & Positive Words In \n The Cat In The Hat Kids' Book \n With The bing Lexicon \n") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_text(face="bold", colour="darkblue", size = 12),
axis.title.y = element_text(face="bold", colour="darkblue", size = 12),
strip.background = element_rect(fill = "#BEE1D3"),
strip.text.x = element_text(size = 10, face = "bold", colour = "black")) +
scale_fill_manual(values=c("#FF0000", "#01DF3A"), guide=FALSE) +
coord_flip()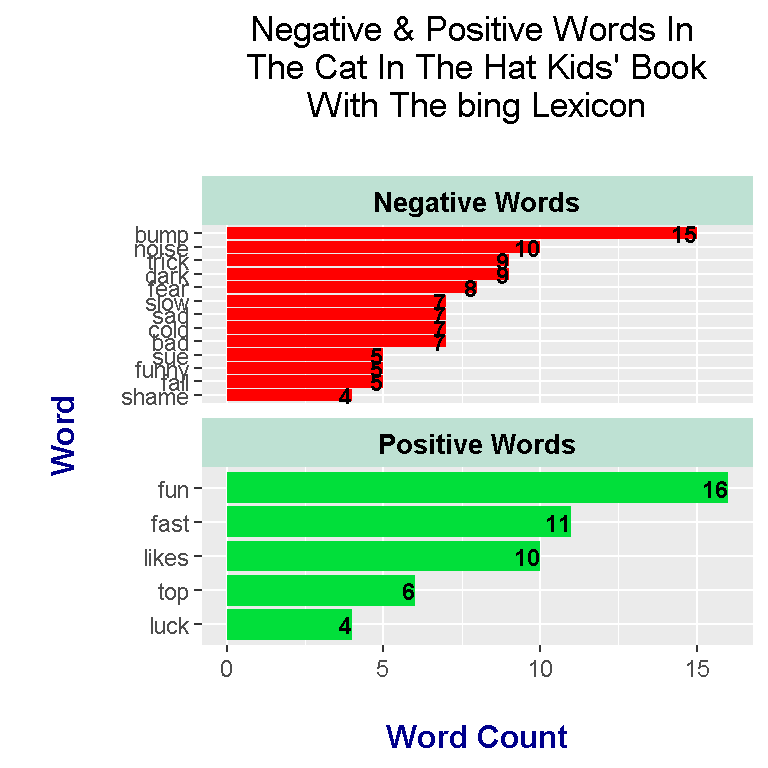
The top negative word according to bing is bump. Other intriguing negative words include sue, funny, trick and noise. The word sue is either a verb as in to sue someone or it could be a name. I am not sure if I agree funny being a negative word. The word trick can be used as a verb as in to trick someone or as a noun such as a magic trick. Bing interprets trick more as a verb I presume.
AFINN Lexicon
Words from the AFINN lexicon are given a score from -5 to + 5 (whole numbers only). Scores below zero are for negative words and positive numbers are for positive words. I have used the mutate() function from R’s dplyr package to add a new column which indicates whether a word is positive or negative. This extra column helps in creating separate plots into one plot under ggplot2.
### AFINN lexicon:
# Change labels
# (Source: https://stackoverflow.com/questions/3472980/ggplot-how-to-change-facet-labels)
catHat_book_words_AFINN <- catHat_book_wordcounts %>%
inner_join(get_sentiments("afinn"), by = "word") %>%
mutate(is_positive = score > 0)
head(catHat_book_words_AFINN, n = 15)## # A tibble: 15 x 4
## word n score is_positive
## <chr> <int> <int> <lgl>
## 1 fun 16 4 TRUE
## 2 battle 11 -1 FALSE
## 3 likes 10 2 TRUE
## 4 stop 9 -1 FALSE
## 5 fear 8 -2 FALSE
## 6 bad 7 -3 FALSE
## 7 dear 7 2 TRUE
## 8 sad 7 -2 FALSE
## 9 top 6 2 TRUE
## 10 blocks 5 -1 FALSE
## 11 funny 5 4 TRUE
## 12 fan 4 3 TRUE
## 13 fight 4 -1 FALSE
## 14 luck 4 3 TRUE
## 15 shame 4 -2 FALSEword_labels_AFINN <- c(
`FALSE` = "Negative Words",
`TRUE` = "Positive Words"
)
catHat_book_words_AFINN %>%
filter(n > 3) %>%
ggplot(aes(x = reorder(word, n), y = n, fill = is_positive)) +
geom_bar(stat = "identity", position = "identity") +
geom_text(aes(label = n), colour = "black", hjust = 1, fontface = "bold", size = 3.2) +
facet_wrap(~is_positive, scales = "free_y", nrow = 2, labeller = as_labeller(word_labels_AFINN)) +
labs(x = "\n Word \n", y = "\n Word Count ", title = "Negative & Positive Words In \n The Cat In The Hat Kids' Book \n With The AFINN Lexicon \n",
fill = c("Negative", "Positive")) +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_text(face="bold", colour="darkblue", size = 12),
axis.title.y = element_text(face="bold", colour="darkblue", size = 12),
strip.background = element_rect(fill = "#D5ADA4"),
strip.text.x = element_text(size = 10, face = "bold", colour = "black")) +
scale_fill_manual(values=c("#FF0000", "#01DF3A"), guide=FALSE) +
coord_flip()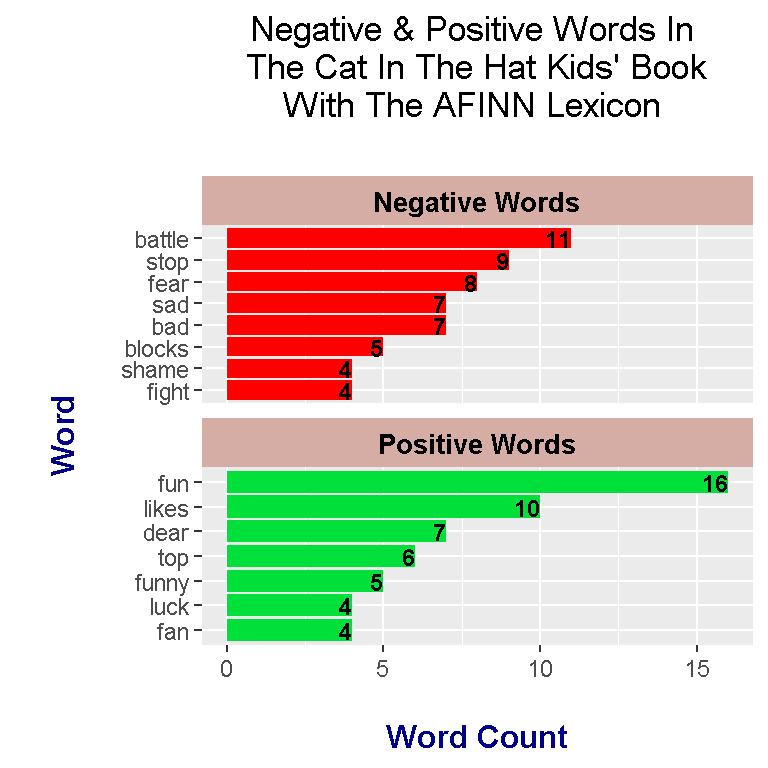
Under AFINN, the most negative word is battle and the most positive word is fun. The word fun is featured in all three lexicons and the “negative” word bad is featured in all three as well. As different as these lexicons are in terms of categorization, there are a few common words between the three lexicons.
The nrc lexicon scores the The Cat In The Hat book more positively than bing and AFINN. bing gives the book a more negative score overall and the AFINN results are fairly balanced.
References
- R Graphics Cookbook By Winston Chang
- Text Mining With R: A Tidy Approach By Julia Silge & David Robinson
- http://www.sthda.com/english/wiki/text-mining-and-word-cloud-fundamentals-in-r-5-simple-steps-you-should-know
- https://www.youtube.com/watch?v=JoArGkOpeU0
- https://github.com/robertsdionne/rwet/blob/master/hw2/drseuss.txt
- https://stackoverflow.com/questions/3472980/ggplot-how-to-change-facet-labels